Verification Engineerの戯言さんのところでOVMのガイドラインを紹介されていたのでダウンロードして見てみる。
http://blogs.yahoo.co.jp/verification_engineer/62124940.html
automation macrosとかdefault sequenceとかsequence macrosとかpre_body()/post_body()とか、使ってたものがことごとく否定されてるんですが。。。
見直さなきゃなぁ。
でもしばらく使ってなかったし、またすぐ使う予定でもないし。
今度使うとき考えよう。
火曜日, 5月 18, 2010
火曜日, 4月 13, 2010
Constant Function
 |
| by Jorge Franganillo |
使い用によっては便利だなと思いつつ、使わなくてもなんとかなるものなのであまり気にしていませんでしたが、使いたくなったときに調べるのが面倒なのでメモしときます。
まずどういうときに使うのかというと、使いたい時というのは多分限られていて例えばFIFOなどのパラメータ化を考えたとき、昔のVerilog HDLではパラメータとしてデータのビット幅とFIFOの深さそれとFIFOのポインタのビット幅をという3つのパラメータを指定する必要がありました。
この中でFIFOのポインタのビット幅というのはFIFOの深さから導けるのですが、単純な四則演算などで計算することが出来ず、for文などを使う必要があるため別途パラメータとして渡してあげなければならなかったわけです。
例えば次のような感じです。
module my_fifo (clk, rst_n, we, re, wdt, rdt, full, empty); parameter DT_WIDTH = 8; parameter FIFO_DEPTH = 16; parameter PTR_WIDTH = 4; input clk, rst_n, we, re; input [DT_WIDTH-1:0] wdt; output [DT_WIDTH-1:0] rdt; output full, empty; reg [DT_WIDTH-1:0] ram [0:FIFO_DEPTH-1]; reg [PTR_WIDTH-1:0] wr_ptr; reg [PTR_WIDTH-1:0] rd_ptr; ...; endmoduleそれがVerilog2001からは演算結果が定数となる場合であれば、parameterの右辺にfunctionを使えるようになったため以下のように書けるので、パラメータの受け渡しの際にFIFO_DEPTHとPTR_WIDTHの間で不整合が起こるような危険を回避できます。
module my_fifo (clk, rst_n, we, re, wdt, rdt, full, empty); parameter DT_WIDTH = 8; parameter FIFO_DEPTH = 16; localparam PTR_WIDTH = log2(FIFO_DEPTH); input clk, rst_n, we, re; input [DT_WIDTH-1:0] wdt; output [DT_WIDTH-1:0] rdt; output full, empty; reg [DT_WIDTH-1:0] ram [0:FIFO_DEPTH-1]; reg [PTR_WIDTH-1:0] wr_ptr; reg [PTR_WIDTH-1:0] rd_ptr; ...; endmoduleここでlog2()は2を底とする入力の対数を計算するfunctionとします。
で、この2を底とする入力の対数を求めるfunctionなんですがConstant Functionの例では必ずと行っていいほどこの例になっています。しかし、なかには間違えているコードもあるようなのでご注意ください。
例えばこちらの"3.0 LRM Errors"ではIEEE Verilog-2001 Standardで紹介されている次のコードに誤りがあると指摘しています。
//define the clogb2 function
function integer clogb2;
input depth;
integer i,result;
begin
for (i = 0; 2 ** i < depth; i = i + 1)
result = i + 1;
clogb2 = result;
end
endfunction
どこが悪いのかわかりますか?1つは入力のdepthが1ビットとなっていること。
そしてもうひとつはdepthが1だった場合にforループが実行されず、resultが初期化されないためにこのfunctionが不定値を返してしまうことです。
そこでこのfunctionは次のように置き換えるべきだと書いてあるのですが。。。
function integer clogb2;
input [31:0] value;
for (clogb2=0; value>0; clogb2=clogb2+1)
value = value>>1;
endfunction
これはこれで問題がある気がします。入力が2の定数である場合、結果が正しくないですよね?
例えば入力value=2の時、1を返すのが正しい結果のはずですがforループが2回実行されるので結果2を返してしまいます。
こちらで紹介されている例のほうが良いでしょう。
function integer log2;
input integer value;
begin
value = value-1;
for (log2=0; value>0; log2=log2+1)
value = value>>1;
end
endfunction
入力が0だと問題ですが、対数を求める関数なのでもともと入力は1以上であるはずです。使う機会はそれほど多くないかもしれませんが覚えておいて損はないでしょう。
金曜日, 4月 09, 2010
SystemVerilogをはじめたい人に
 |
| by magnetbox |
SystemVerilogの世界へようこそ
以前紹介したブログ、Verification Engineerの戯言を書かれている方のサイトです。
OVMやVMMなどの紹介もありますね。
日本語のサイトでは非常に珍しいと思います。
Have a nice experience!
木曜日, 4月 08, 2010
always_combとalways@*の違い
 |
| by Manuel Cernuda |
以前のVerilog HDLでは、alwaysを使って組み合わせ回路を書く場合には
Sensitivity Listに入力を全て列挙しなければならず面倒で、またバグの温床でもありました。
例えばこんな感じです。
always @ ( color or a or b or c or ... ) begin
case (color)
RED : x = a;
BLUE : x = b & c;
....;
endcase
end
Verilog 2001ではalways @*がサポートされてかなりの簡潔に記述できるようになり、Sensitivity Listの記入漏れの問題は起きにくくなりました。
しかし、それでもまだ実はシミュレーション時に問題が起こる可能性があります。
always @* begin
case (color)
RED : x = a;
BLUE : x = b & c;
PINK : x = my_function(d, e, f);
....;
endcase
end
function my_function;
input sig_a;
input sig_b;
input sig_c;
begin
my_function = sig_a | sig_b | sig_c | SIG_X;
end
endfunction
always @*はalways内で直接使用している信号までしかsensitiveではなく、
例えば上の例の様な記述の場合、my_function()の中で使用しているSIG_Xに変化があったとしてもalways @*の出力xは変化しません。
このような問題を解決できるのがSystemVerilogのalways_combです。
always_comb begin
case (color)
RED : x = a;
BLUE : x = b & c;
PINK : x = my_function(d, e, f);
....;
endcase
end
このようにalways @*の場合と同様に記述出来ます(functionの内部は省略)。
しかし、always_combの場合はalways @*と違い、内部に含まれるfunctionが使用している信号に対してもsensitiveになります。つまり、この場合はSIG_Xの変化にもalways_combの出力xが連動します。
その他にも、always_combではalways @*と比べて以下のような違いがあります。
・時刻0で一度always_comb内部が実行される
・always_comb内でドライブされている信号は他の場所でドライブできない
・always_comb内ではwait()やfork...joinなどのタイミングをブロックするような制御が行えない
他にもSystemVerilogではalways_latchやalways_ffなどが追加されていますが特にこのalways_combが重要ですね。
alwaysで組み合わせ回路を記述する場合は是非使うようにしましょう。
最後に、昔書いた組み合わせ回路の記事のリンクを貼っておきます。
ここではalwaysで組み合わせ回路を記述する場合の短所としてregで出力を宣言しなければならないと書きましたが、SystemVerilogでは新たにlogicが追加されたので便利になりました。
functionを使う場合は、always_combの中に入れておくとより安全でしょう。
こちらで別の例が詳細されていたのでリンクしときます。
水曜日, 3月 31, 2010
VCSでマクロ使用時の注意点
 |
| by oddsock |
Have you ever heard of a programming language called "Whitespace"?
VCSでマクロを使った時に痛い目にあったというお話。
長いマクロを記述する場合、'\'(バックスラッシュ)を使って複数行に分けて記述することは多いですよね。
しかし、VCSではバックスラッシュの後にスペースが入っている場合にエラーとなり、しかもそのエラーメッセージが指している場所が変なことになってしまうそうです。
私もちょっとVCSで試してみましたが確かにバックスラッシュの後にスペースを入れるとエラーとなって、そのエラーメッセージでは少しズレた所を指してました。
ちなみにiverilogで同じコードを試してみると大丈夫でした。
記事の方では、SystemVerilogのLRMに従えばこのコードはOKなはずだと書かれているのですが、SystemVerilogのLRMを見ると`define macrosの項には
In Verilog, the ‘define macro text can include a backslash ( \ ) at the end of a line to show continuation on the next line.
と書かれているので、一応バックスラッシュは行末に置く必要があると思います。
ただ、エラーメッセージとしては確かにおかしいですね。
ところで元の記事ではタイトルにもあるように"Whitespace"と呼ばれる言語を紹介しています。
言語の概要についてはwikipedia:Whitespaceを参照ください。
なんと、スペースとタブと改行コードのみによって構成される難解プログラミング言語です。
たとえ色分けされてたとしても普通の人間には読めそうもありませんね。
こんなソースを渡されて検証してくれなんて言われたらまさにブラックボックス検証です。
コードはホワイトスペースなのに。。。
火曜日, 3月 30, 2010
今後の方針
とりあえずブログを再開しようと思ったので心機一転、サイトのデザインをリニューアル。
とはいうものの、どんなネタを書いていこうか迷ってました。
書いてみたいネタ自体は多少あるのだけれども
時間に制限もあるし、仕事の関係もあったりでなかなか制約が厳しい。
そんなことを思いつつ、ネタ探しに海外のブログなんかを久しぶりに見まわってみると2年ぐらい前に比べてLSI機能検証関連の有益な内容の記事が多くあることに気づく。
それに比べて日本(日本語のサイト)はどうだろうか。
私の知る限りではこちら↓ぐらい(他にあれば教えてください)。
Verification Engineerの戯言
海外と日本とで圧倒的な情報量の差がある。
しかも、海外のサイトは英語だけど多分インド出身の人などが書いてるみたい。
冗談ではなく将来の日本の半導体業界が心配になってくる。
そこで、既に海外には有益な情報があるのだからそれをパクってやろう英語を読むのが面倒な日本のエンジニアの方々にも紹介していこうかなと考えてます。
まあただ、英語力にはあまり自信がないし自分の勝手な解釈も入るので英語が得意な方は原文を読んだ方が早いと思いますけどね。
とはいうものの、どんなネタを書いていこうか迷ってました。
書いてみたいネタ自体は多少あるのだけれども
時間に制限もあるし、仕事の関係もあったりでなかなか制約が厳しい。
そんなことを思いつつ、ネタ探しに海外のブログなんかを久しぶりに見まわってみると2年ぐらい前に比べてLSI機能検証関連の有益な内容の記事が多くあることに気づく。
それに比べて日本(日本語のサイト)はどうだろうか。
私の知る限りではこちら↓ぐらい(他にあれば教えてください)。
Verification Engineerの戯言
海外と日本とで圧倒的な情報量の差がある。
しかも、海外のサイトは英語だけど多分インド出身の人などが書いてるみたい。
冗談ではなく将来の日本の半導体業界が心配になってくる。
そこで、既に海外には有益な情報があるのだからそれを
まあただ、英語力にはあまり自信がないし自分の勝手な解釈も入るので英語が得意な方は原文を読んだ方が早いと思いますけどね。
木曜日, 3月 25, 2010
AMBA AXIのINCRバーストアドレスの計算
 |
| Photo by James Cridland |
INCRバーストでアンアラインド転送の場合を考慮してなかったので、注意点を最後に追記しました。
以前にWRAPバーストアドレスの場合を書いたのですがついでなのでINCRバーストの場合も書いておこうと思います。
というか、むしろこっちの方を先に書いておくべきだったような気が。。。
さて、AXIでは1つのバーストのアドレスが4Kbyteの境界をまたいではいけないという制約があります。
したがって、アドレスのカウンタとしては12bitで十分ということになります。
ということで、INCRバーストのアドレスは次のようになります。
always @(posedge ACLK or negedge ARESETn) begin
if (!ARESETn) begin
addr_cnt <= 12'd0;
end
else begin
if ( AWVALID && AWREADY ) begin
if ( WVALID && WREADY )
addr_cnt <= AWADDR[11:0] + ( 12'b1 << AWSIZE );
else
addr_cnt <= AWADDR[11:0];
end
else if ( WVALID && WREADY ) begin
addr_cnt <= addr_cnt + ( 12'b1 << r_awsize );
end
end
end
なんだ、WRAPの場合と同じじゃないか!といわれそうですがその通りです。
なので通常はアドレスカウンタは1つだけ持っておいて、
WRAPバーストの場合は必要な下位のビットだけ使用すれば良いと思います。
もちろん、上位のビットはラッチしといてくださいね。
【追記】アンアラインド転送の場合の注意点
以上の記事を書いている時点では、アンアラインド転送の事を考慮していなかったため、このアドレスカウンタでは不十分な場合があります。
アンアラインドのアドレスをアラインさせるのは以下の方法で行えます。
Aligned_Address = Unaligned_Address & ( {(Addr_Width){1'b1}} << AWSIZE ) アドレスカウンタにロードする際にアドレスをアラインメントさせてスタートアドレスを別に記憶しておいてもいいと思いますし、
最初のカウントアップ(または全てのカウントアップ)の時にアラインメントする方法もあります。
もしくはアドレスの計算自体は上記の方法そのままで、出力するときにアラインメントするなど。
方法はいろいろ考えられますが、都合の良い実装方法で行ってください。
ただ実は、スレーブにおいては転送サイズさえ見ておいて、アドレスの下位の部分についてはWSTRBを信用すれば良いので、アドレスがちゃんと転送サイズにアラインメントされていようがいまいが関係なかったりします。
ブリッジなどの場合はアドレスを正しく伝える必要があるかもしれないのでその場合は注意してください。
火曜日, 3月 16, 2010
仕様を明確化する
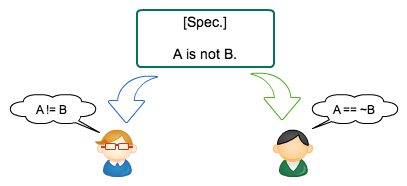
[曖昧な仕様の解釈は人それぞれ]
勿論、開発の初期段階で全ての仕様を明確にするのはほぼ不可能だと思うので、実際の工程では仕様の不明な点が見つかる毎に明確化させていくという手順を踏むことになると思います。
ここで重要なのは、不明な点をそのままにしておかないという事。「ここは多分こうだろう」と勝手に決めて実装してしまうのは非常に危険です。
多くの場合、人は自分の都合の良いように仕様を解釈します。という事は、かなりの確率でインタフェース相手の考えはあなたの考えとは異なるでしょう。
HDLで実装した後に、仕様が変更されると非常にエネルギーを浪費します。また、ハードの場合はさらにその先で仕様の不備が発覚すると莫大なコストが発生することも。
はじめは面倒かもしれませんが、コツコツと仕様を明確化して行く事が結果的には品質の向上とコストダウン、そしてストレスフリーにつながります。
金曜日, 3月 12, 2010
AMBA AXIのWrapアドレスの計算
前回、AMBA AXIのWrap Boundaryを計算しました。
折角なのでWRAPバーストの場合のアドレスの計算もやってみようと思います。とは言ってもWrap Boundaryが算出できればそれほど難しくはありません。
まず前提条件ですが、AXIのWRAPバーストでは以下の制約があります。
・開始アドレスは転送サイズにアラインメントされていなければならない
・バースト長は2,4,8または16のいずれかでなければならない
なので、前回のBoundaryの計算も含め、ここではこの制約を前提としています。
さて、アドレスを計算するにはアドレスカウンタを作ると思いますがAXIのWRAPバーストの場合、このカウンタは何ビットのものが必要かというと、転送サイズとバースト長の最大値がそれぞれ128Byteと16ビートなので
log2(128*16) = 11ビット
となります。11ビットのライトアドレスカウンタをwaddr_cntとすると次のように書けます。
always @(posedge ACLK or negedge ARESETn) begin
if (!ARESETn) begin
waddr_cnt <= 11'd0;
end
else begin
if ( AWVALID && AWREADY ) begin
if ( WVALID && WREADY )
waddr_cnt <= AWADDR[10:0] + ( 11'b1 << AWSIZE );
else
waddr_cnt <= AWADDR[10:0];
end
else if ( WVALID && WREADY ) begin
waddr_cnt <= waddr_cnt + ( 11'b1 << r_awsize );
end
end
end
ここで、r_awsizeはAWSIZEをラッチしたものです。データチャネルがアドレスチャネルよりも先に成立する場合は考慮してません。
そうならないよう、WREADYを制御する(;^_^A
あらかじめ断っておきますが、このコードは実際に検証を行っていませんのでちゃんと動くかどうかわかりません。なんとなくこんな感じで実装できるよというのがわかっていただければ幸いです。
あとはこのアドレスカウンタと前回計算したWrap BoundaryをくっつければWRAPバースト時のアドレスが決まります。こんな感じですね。
assign wrap_waddr = Wrap_Boundary | ( waddr_cnt & ~( { {(Addr_Width-4){1'b1}}, ~r_awlen } << r_awsize ) );
Addr_Widthはアドレスの幅で、r_awlenはAWLENをラッチしたものです。実際は転送サイズは16Byteまでなどといった場合が多いと思うのでカウンタのサイズはもう少し小さくできると思います。
木曜日, 3月 11, 2010
AMBA AXIのWrap Boundaryの計算
何年ぶりかの更新なのですがそんなことは特に気にせずメモがわりに書きます。
AMBA AXI Protocol v1.0 SpecificationにはWrap Boundaryの定義として
Wrap_Boundary =
( INT ( Start_Address / ( Number_Bytes x Burst_Length ) ) ) x ( Number_Bytes x Burst_Length )
とあります。
一瞬軽いイジメかと思うが、丁寧に見ると要は(転送サイズ×バースト長)にアラインメントさせたアドレスという感じの意味。
ここで、
INT(x) はxを小数点以下切り捨てで整数にした値
Start_Addressは転送のスタートアドレス
Number_Bytesは転送サイズ(単位バイト)= 2^AWSIZE または 2^ARSIZE
Burst_Lengthはバースト長 = AWLEN+1 または ARLEN+1
アドレスの幅をAddr_WidthとするとVerilogでは次のように書けます。たぶん。
(Writeの場合)
Wrap_Boundary = Start_Address & ( { {(Addr_Width-4){1'b1}}, ~AWLEN } << AWSIZE )
ハードは便利だ。
Readの場合はAWLEN,AWSIZEをそれぞれARLEN, ARSIZEに変えます。
ちなみにAXIではWRAPバーストの場合バースト長は2,4,8,16のいずれかでなければなりません。
なのでWRAPバースト時にAWLEN/ARLENが取り得る値は4'b0001, 4'b0011, 4'b0111, 4'b1111のいずれかです。
登録:
コメント (Atom)